Finding the Perfect Guitar on Sweetwater

Motivation
Sweetwater is a great place to shop online for a guitar. One reason for this is that they display real images of guitars they have in stock, and let you choose the one you like best. I was in the market for a Les Paul, but the finish varies (sometimes dramatically) from guitar to guitar due to the burst being done by hand. After internally debating between two different Iced Tea bursts for the better part of an hour, I finally decided to pull the trigger. As I go to the checkout menu, I find, much to my dismay, that the one I had chosen had been sold during my bout of indecisiveness. I didn’t like the finish of the other guitar they had in stock as much, so I decided I’d wait for more stock. Being the impatient person that I am, I knew I would be refreshing the page hourly to try to snatch up a good looking one when it came in stock. That would probably end up driving me crazy. So, naturally, I started looking for an opportunity to automate this task.
Research
The general idea was to create a program that can:
- Fetch in-stock listings from Sweetwater
- Send a notification when the program detects a listing is new
- Append an image and a link to the listing in the notification
In order to do this, I started looking at the product page for the guitar I was interested in and noticed a few key pieces of identifying information. First, every product has a unique item ID listed on the page. Second, each guitar for a given item ID has an associated serial number. So the initial plan for the script was to check the webpage with the URL https://www.sweetwater.com/store/detail/{item id} and try to fetch a list of the serial numbers available on that page. The script would then compare the current listings with the previously seen listings to detect any new serial numbers.
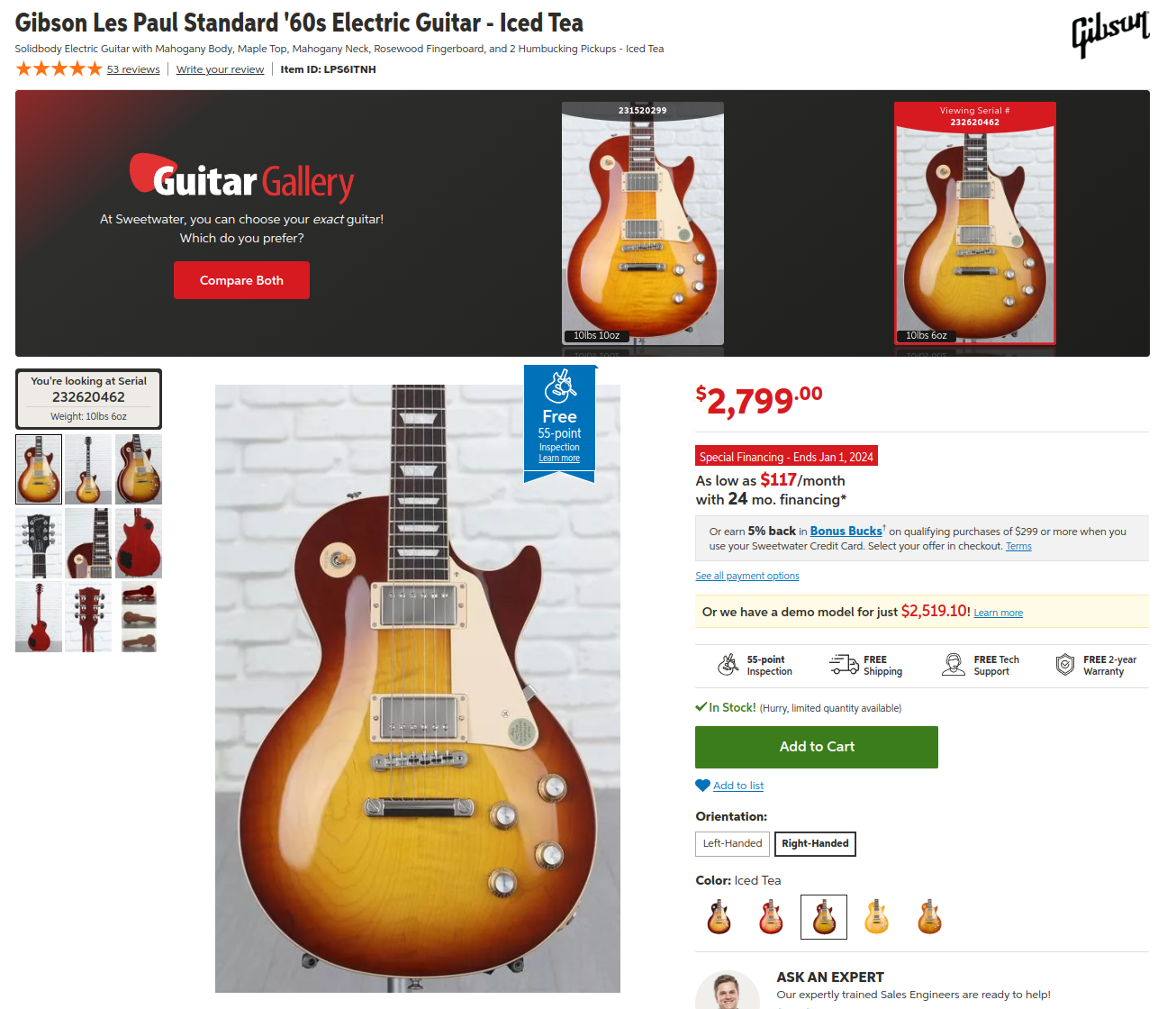 Sweetwater product page
Sweetwater product page
Scraping Sweetwater
The typical way to scrape a website is to perform an HTTP get request to fetch the site’s HTML content, parse it, and search it for the identifying information you’re looking for. In this case, I noticed that all the serial numbers are listed in the “Guitar Gallery” header, and the serial number for the currently selected guitar is listed on the left-hand side. So I opened the Chrome developer console and started searching for the serial numbers to see where they are in the HTML source.
 Sweetwater HTML source
Sweetwater HTML source
Sure enough, the serial numbers are in listed in the serial-header__photos block. This could be parsed and the serial numbers could be extracted. The trouble is, the Guitar Gallery is only visible when there is more than one guitar in stock. If there is only one guitar in stock, there is no Guitar Gallery. This could be worked around by looking for the Guitar Gallery, and if it’s not there, using the left-hand side current serial number field instead. Ultimately, this was starting to feel ugly, so I decided to try a different approach.
Another way to scrape a website is by monitoring network traffic on the site and looking for API calls in the HTTP requests. To do this, I opened Chrome’s Network tab in the developer console and refreshed the page. I then searched again for the serial number and found an HTTP request that returned a JSON object with exactly what I needed! The object contained the current available serial numbers, the URL’s of their images, the product name, and tons of other useful information.
 Sweetwater API call
Sweetwater API call
The plan became a lot more simple. All that was needed was to make an HTTP request to the API, and parse the resulting JSON object.
Writing the Script
Python was my language of choice because it’s trivial to make HTTP requests and work with JSON. I started by testing out the HTTP request:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import requests
id: str = LPS6ITNH
url: str = f"https://www.sweetwater.com/webservices_sw/items/detail/{id}?format=serialcompare"
headers: dict = {
# otherwise we get a 403 error
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
}
try:
with requests.Session() as session:
request = session.get(url, headers=headers)
except requests.HTTPError as e:
raise IOError(
f"ERROR: failed to fetch products ({e.response.status_code})"
) from e
try:
data = json.loads(request.text)
except json.JSONDecodeError as e:
raise IOError("ERROR: Failed to parse product JSON") from e
Initially, the request would return a 403 Forbidden error. This was solved by populating the User-Agent field of the HTTP header, which provides some identifying information about the browser and the host OS to the web server. Some websites will block HTTP requests without this field to prevent non-browsers such as web scrapers from making requests.
After this was working, I unpacked the JSON results into a Python object. I store the resulting objects in a set, which has the nice property of ignoring duplicate entries and supporting a set-difference operation to find objects belonging to one set but not another.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class SweetwaterProduct:
def __init__(self, name: str, serial: int, url: str, images: list) -> None:
self.name: str = name
self.serial: int = serial
self.url: str = url
self.images: list = images
def __eq__(self, other) -> bool:
if isinstance(other, SweetwaterProduct):
return self.serial == other.serial
return False
def __hash__(self) -> int:
return hash(self.serial)
products: set = set()
name: str = data["productName"]
try:
items: set = set(
map(
lambda item: SweetwaterProduct(
name=name,
serial=int(item["serialNumber"]["number"]),
url=f'https://www.sweetwater.com{item["serialUrl"]}',
images=[
item["images"][view]["images"]["750"]["absolutePath"]
for view in ["angle"] # can also use body, front, back
],
),
data["comparableSerials"],
)
)
except (KeyError, ValueError) as e:
raise IOError("ERROR: Invalid key access when parsing product JSON") from e
products |= items
With this code in place, finding new products is as simple as new_product = products - seen_products. And as a bonus, sold products can also by computed by sold_products = seen_products - products.
To handle notifications, I decided to use a Discord Webhook. This enables posting content to a specific channel in a specific server by performing an HTTP post to a URL, which was enough for my needs.
1
2
3
4
5
6
7
8
9
10
11
12
13
def post_discord(webhook: str, message: str, roles: list = []) -> None:
content: str = ""
for role in roles:
content += f"@{role} "
content += f"\n\n{message}"
data: dict = {"content": content, "username": "SweetwaterBot"}
try:
requests.post(webhook, json=data)
except requests.HTTPError as e:
raise IOError(
f"ERROR: failed to post to discord ({e.response.status_code})"
) from e
Results
Ultimately, I left the script running on a Raspberry Pi checking Sweetwater every 5 minutes. The discord integration provides a link and an image of new listings, notifications when listings are sold, and supports watching multiple different item IDs simultaneously.
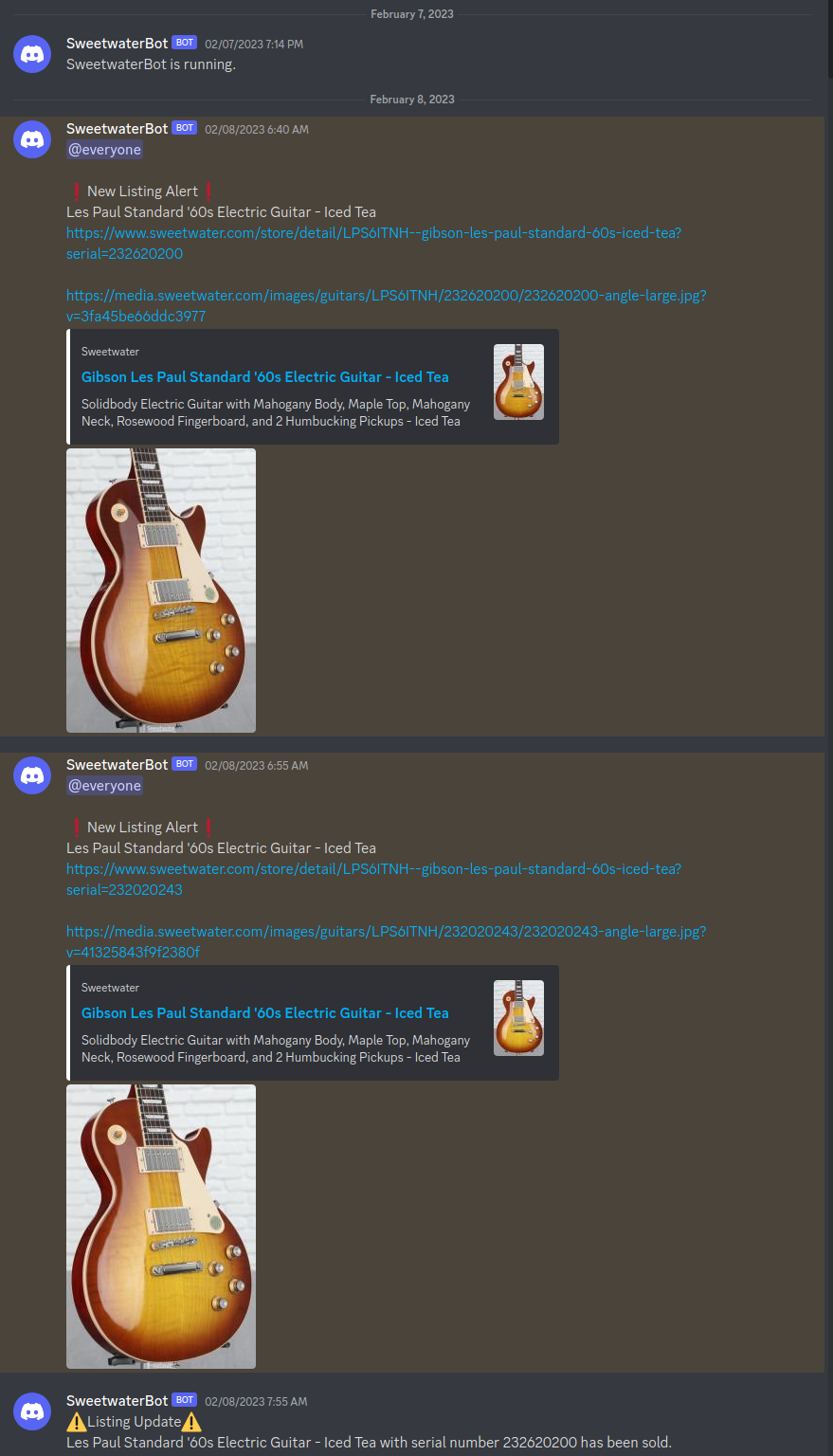 The Discord notifications
The Discord notifications
If I were to continue developing this project, I would replace the Discord webhook with a full-fledged Discord bot, and allow the watchlist to be editable by interacting with the bot instead of hard-coding the watchlist. In the future I’d like to explore making a general purpose Discord bot with support for plugins that could be added in, like this one.
After spending about 6 hours writing this script, I ended up purchasing a guitar only one day later. So was the script necessary? Probably not. But it was a lot of fun to write and taught me something new about web scraping. Plus, I’m very happy with the guitar I ended up with.
 My Gibson Les Paul Standard 60’s Iced Tea
My Gibson Les Paul Standard 60’s Iced Tea
Feel free to check out the code here.